Розпізнавання тексту в PDF-файлах за допомогою OCR
Часто доводиться користуватись інформацією зі сканів або фото документів? Оптичне розпізнавання символів (OCR) в PDF Expert дозволить вам перетворити скани в текст, який можна виділяти, копіювати, шукати в ньому.
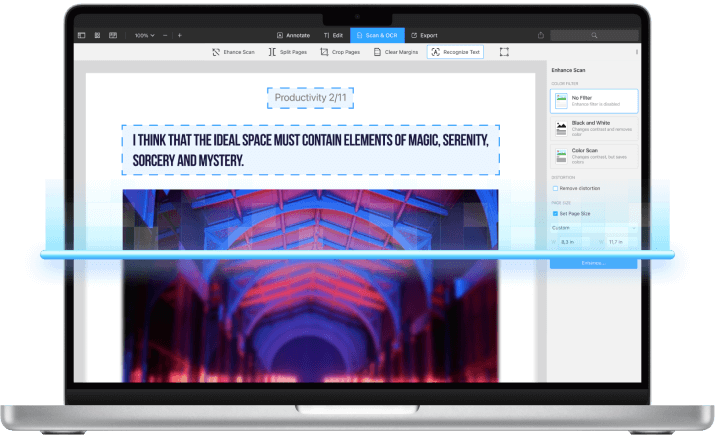
Що таке OCR і як воно може вам допомогти?
Деякі PDF-файли, наприклад, відскановані книги або квитанції, не підтримують пошук і не дозволяють виділяти текст. Функція оптичного розпізнавання символів (OCR) у PDF Expert розпізнає текст у відсканованих файлах з найвищим рівнем точності та разючою швидкістю.

Почніть роботу з
PDF Expert вже сьогодні
Витягнення тексту із зображень
Заощаджуйте час, легко витягуючи та копіюючи текст зі сканованих документів або фотографій за допомогою технології OCR у PDF Expert.

Виділення тексту у сканах
Розпізнайте текст у відсканованих книгах або журналах і ви зможете анотувати їх так само, як і будь-які інші PDF-файли.

Почніть роботу з
PDF Expert вже сьогодні
Зробіть скановані PDF доступними для пошуку
Заощаджуйте час і здійснюйте пошук у всіх відсканованих документах завдяки швидкому і точному розпізнаванню тексту.

Розпізнавайте текст понад 20 мовами
Розпізнавання тексту в PDF Expert підтримує українську, англійську, німецьку, французьку, японську, італійську, іспанську, спрощену та традиційну китайську, португальську та інші мови.

Почніть роботу з
PDF Expert вже сьогодні
Як розпізнати текст у PDF за допомогою OCR
Перегляньте це коротке відео, щоб дізнатися, як розпізнати текст у відсканованих книгах або журналах, щоб ви могли копіювати, виділяти текст або шукати будь-що у своїх документах.
Встигайте більше з PDF Expert
Почніть роботу з
PDF Expert вже сьогодні
Тепер набагато легше редагувати, анотувати, підписувати та впорядковувати PDF.